[MySQL] B-Tree 인덱스
인덱스를 생성하는 도중 의문에 생겼다.

다중컬럼 인덱스를 생성하면 단일컬럼인덱스를 왜 또 생성해주어야할까?
다중컬럼 인덱스를 걸어두면 단일컬럼 조회 시에도 인덱스 스캔을 타야 하는 것이 아닐까?
B-Tree 인덱스 구조를 파헤쳐보면 이 문제에 대한 해답을 얻을 수 있었다.
인덱스란?
- 인덱스는 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조를 뜻한다.
- 즉 데이터를 빨리 찾기 위해 특정 컬럼을 기준으로 미리 정렬해 놓은 표 라고 이해하면 쉽다.
인덱스의 장단점
- 인덱스는 항상 정렬된 상태를 유지하기 때문에 원하는 값을 검색하는데 빠르지만, 새로운 값을 추가하거나 삭제, 수정하는 경우에는 쿼리문의 실행 속도가 느려집니다.
- 즉, 인덱스는 저장성능을 희생하고 그 대신 데이터의 검색 속도를 높이는 기능이라 할 수 있습니다.
B- Tree 인덱싱 알고리즘 알아보기
대부분의 인덱스는 거의 B-Tree 를 사용할 정도로 일반적이 용도에 적합한 알고리즘이다.
검색 속도가 O(1) 인 해시테이블 알고리즘은 왜 사용하지 않을까?
- 해시 테이블
- 컬럼의 값으로 생성된 해시를 기반으로 인덱스를 구현합니다
- 시간 복잡도가 O(1) 이라 검색이 매우 빠릅니다.
- 부등호(<,>) 와 같이 연속적인 데이터를 위한 순차 검색이 불가능하기 때문에 사용에 적합하기 않습니다.
B-Tree 의 구조 및 특성
B-Tree 는 트리 구조의 최상위에 "루트 노드" 가 존재하고 그 하위에 자식 노드가 붙어있는 형태다.
- 트리 구조의 가장 하위에 있는 노드를 "리프 노드" 라 하고, 트리 구조에서 투르, 리프도 아닌 중간노드를 "브랜치 노드"라 한다.
- 데이터 베이스에서 인덱스와 실제 데이터가 저장된 데이터는 따로 관리가 되는데, 인덱스의 리프 노드는 항상 실제 데이터 레코드를 찾아가기 위한 주소값을 가지고 있다.
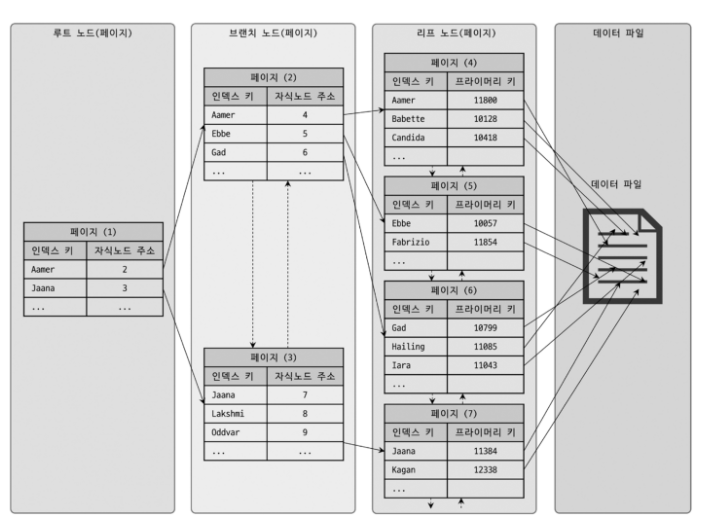
인덱스의 키 값은 모두 정렬돼 있지만, 데이터 파일의 레코드는 정렬돼 있지 않고 임의의 순서로 저장돼 있다.
페이지란?
- 디스크와 메모리 사이에서 데이터를 주고받는 단위 블록.
- DBMS는 디스크에서 데이터를 한 줄(row) 단위로 읽지 않고, "페이지 단위로 읽고 씀".
- 보통 1 page = 4KB, 8KB, 16KB 등 (DBMS마다 다름, MySQL은 보통 16KB)
인덱스와 페이지
- 인덱스( B-tree 등)는 계층적으로 구성돼 있다.
- 루트 페이지
- 브랜치 (중간) 페이지
- 리프(leaf) 페이지 : 실제 인덱스 값과 포인터 (ROWID 등) 가 있음
각각이 다 하나의 페이지로 구성된다. 즉 B-tree 인덱스는 페이지 트리(Page Tree) 라고 볼 수 있다
중요성
디스크 I/O 최적화
- 페이지 단위로 읽고 쓰니까, I/O 효율성을 위해 페이지 크기가 중요하다.
- 자주 쓰는 페이지는 메모리에 캐시된다. (buffer pool).
캐시 히트율
- 특정 인덱스 페이지가 자주 쓰이면 RAM 에 계속 머무르고 조회성능이 빨라짐.
- 반대로 페이지 수가 너무 많으면, 캐시 적중률이 낮아져 성능 하락.
인덱스 리벨런싱/ 압축
- 페이지가 꽉 차거나 비게 되면 split 또는 merge가 일어남.
- 이건 인덱스 성능에 영향을 줄 수 있음.
- 페이지 분할 작업은 시간이 많이 걸리는 작업임.

그림으로 비유하자면:
- 인덱스 전체 = 커다란 책
- 각 페이지(Page) = 책의 한 장
- RAM = 책상 위의 공간 (한 번에 올릴 수 있는 페이지 수 제한)
- 디스크 = 책장 (꺼낼 때 시간 오래 걸림)

B-Tree 인덱스를 통한 데이터 읽기
다중 컬럼 인덱스
- 두 개 이상의 컬럼으로 구성된 인덱스를 다중 컬럼 인덱스(Concatendated Index)한다.
- 다중 컬럼에서는 다음 컬럼이 이전컬럼에 의존해서 정렬된다고 한다.
- 다중 컬럼 인덱스에서는 인덱스 내에서 각 컬럼의 위치(순서)가 상당히 중요하다.

emp_no 값이 빠르더라도 dept_no 컬럼의 정렬 순서가 늦다면 인덱스는 뒤쪽에 위치하게 된다.
두 번째 컬럼 만으로 질의하는 경우는 인덱스를 타지 못하게 된다. 즉 두 번째 컬럼의 정렬은 첫 번째 컬럼이 동일한 레코드에서만 의미가 있는것이다. 그래서 다중 컬럼 인덱스에서는 인덱스 내에서 각 컬럼의 위치(순서)가 상당히 중요하다.
참고자료 :
https://dev-coco.tistory.com/158
Real MySQL 8.0