생산자 소비자 문제 - 소개
생산자 소비자 문제는 멀티스레드 프로그래밍에서 자주 등장하는 동시성 문제 중 하나로, 여러 스레드가 동시에 데이터를 생성하고 소비하는 상황을 다룬다.
멀티스레드의 핵심을 제대로 이해하려면 반드시 생산자 소비자 문제를 이해하고, 올바른 해결방안도 함께 알아두어야 한다.
생산자 소비자 문제를 제대로 이해하면 멀티스레드를 제대로 이해했다고 볼 수 있다. 그만큼 중요한 내용이다.
프린터 예제 그림

기본 개념
- 생산자(Producer)
- 데이터를 생성하거나 작업을 요청하는 역할. 예를 들어, 파일에서 데이터를 읽어 오거나 네트워크에서 데이터를 받아오는 스레드가 생산자 역할을 할 수 있다
- 프린터 예제에서 사용자의 입력을 프린터 큐에 전달하는 스레드가 생산자의 역할이다.
- 소비자(Consumer)
- 생산자가 요청한 데이터를 처리하거나 작업을 수행하는 역할. 예를 들어, 데이터를 처리하거나 저장하는 스레드가 소비자의 역할을 할 수 있다.
- 프린트 예제에서 프린터 큐에 전달된 데이터를 받아서 출력하는 스레드가 소비자 역할이다.
- 버퍼(Buffer)
- 생산자가 생성한 데이터를 일시적으로 저장하는 공간이다. 이 버퍼는 한정된 크기를 가지면, 생산자와 소비자가 이 버퍼를 통해 데이터를 주고받는다.
- 프린트 예제에서 프린터 큐가 버퍼 역할이다.
문제 상황
생산자가 너무 빠를 때 : 버퍼가 가득 차서 더 이상 데이터를 넣을 수 없을 때까지 생산자가 데이터를 생성한다. 버퍼가 가득 찬 경우 생산자는 버퍼에 빈 공간이 생길 때까지 기다려야 한다.
소비자가 너무 빠를 때 : 버퍼가 비어서 더 이상 소비할 데이터가 없을 때까지 소비자가 데이터를 처리한다. 버퍼가 비어있을 때 소비자는 버퍼에 새로운 데이터가 들어올 때까지 기다려야 한다.
생산자 소비자 문제 - 비유
비유 1 : 레스토랑 주방과 손님
- 생산자(Producer) : 주방 요리사
- 소비자(Consumer) : 레스토랑 손님
- 버퍼(Buffer) : 준비된 음식이 놓이는 서빙 카운터
- 요리사 (생산자)는 음식을 준비하고 서빙 카운터(버퍼)에 놓는다.
- 손님(소비자) 은 서빙 카운터에서 음식을 가져가서 먹는다.
- 만약 서빙 카운터에 가득 차면 요리사는 새로운 음식을 준비하기 전에 공간이 생길 때까지 기다려야 한다.
- 반대로, 서빙 카운터에 비어있으면 손님은 새로운 음식이 준비될 때까지 기다려야 한다.
비유 2 : 음료 공장과 상점
- 생산자(Producer) : 음료 공장
- 소비자(Consumer) : 상점
- 버퍼(Buffer) : 창고
- 음료 공장(생산자) 은 음료를 생산하고 창고(버퍼)에 보관한다.
- 상점(소비자) 은 창고에서 음료를 가져와 판매한다.
- 만약 창고가 가득 차면 공장은 새로운 음료를 생산하기 전에 공간이 생길 때까지 기다려야 한다.
- 반대로, 창고가 비어있으면 상점은 새로운 음료가 창고에 들어올 때까지 기다려야 한다.
이 문제는 다음 두 용어로 불린다. 참고로 둘 다 같은 뜻이다.
- 생산자 소비자 문제 (producer-consumer problem) : 생산자 소비자 문제는, 생산자 스레드와 소비자 스레드가 특정 자원을 함께 생산하고 , 소비하면서 발생하는 문제이다.
- 한정된 버퍼 문제(bounded-buffer problem) : 이 문제는 결국 중간에 있는 버퍼의 크기가 한정되어 있기 때문에 발생한다. 따라서 한정된 버퍼 문제라고도 한다.
생산자-소비자 문제는 다음과 같은 조건에서 발생한다.
- 데이터를 처리하기 위해 큐가 필요하고,
- 생산자와 소비자의 속도가 다르며,
- 큐가 가득 차거나 비는 상황에서 대기 상태가 요구되는 경우.
예제를 통해서 생산자 소비자 문제가 왜 발생하는지, 그리고 어떤 해결 방안들이 있는지 예제 코드를 통해서 알아보자
생산자 소비자 문제 - 예제 1 코드
package thread.bounded;
public interface BoundedQueue {
void put(String data);
String take();
}
- BoundedQueue : 버퍼 역할을 하는 큐의 인터페이스이다.
- put(data) : 버퍼에 데이터를 보관한다. (생산자 스레드가 호출하고, 데이터를 생산한다.)
- take() : 버퍼에 보관된 값을 가져간다. (소비자 스레드가 호출하고, 데이터를 소비한다.)
package thread.bounded;
import java.util.ArrayDeque;
import java.util.Queue;
import static util.MyLogger.log;
public class BoundedQueueV1 implements BoundedQueue {
private final Queue<String> queue = new ArrayDeque<>();
private final int max;
public BoundedQueueV1(int max) {
this.max = max;
}
@Override
public synchronized void put(String data) {
if(queue.size() == max) {
log("[put] 큐가 가득 참, 버림 " + data);
return;
}
queue.offer(data);
}
@Override
public synchronized String take() {
if(queue.isEmpty()) {
return null;
}
return queue.poll();
}
@Override
public String toString() {
return queue.toString();
}
}
BoundedQueueV1 : 한정 된 버퍼 역할을 하는 가장 단순한 구현체이다.
Queue, ArrayDeque : 데이터를 중간에 보관하는 버퍼로 큐(Queue)를 사용한다. 구현체로는 ArrayDeque를 사용한다.
int max : 한정된 (Bounded) 버퍼이므로, 버퍼에 저장할 수 있는 최대 크기를 지정한다.
put() : 큐에 데이터를 저장한다. 큐가 가득 찬 경우 더는 데이터를 보관할 수 없으므로 데이터를 버린다.
take() : 큐의 데이터를 가져간다. 큐의 데이터가 없는 경우 null을 반환한다.
toString() : 버퍼 역할을 하는 queue 정보를 출력한다.
임계 영역
여기서 핵심 공유 자원은 바로 queue (ArrayDeque)이다. 여러 스레드가 접근할 예정이므로 synchronized를 사용해서 한 번에 하나의 스레드만 put() 또는 take()를 실행할 수 있도록 안전한 임계영역을 만든다.
예) put(data)을 호출할 때 queue.size()가 max 가 아니어서, queue.offer() 를 호출하려고 한다. 그런데 호출하기 직전에 다른 스레드에서 queue 에 데이터를 저장해서 queue.size() 가 max로 변할 수 있다!
package thread.bounded;
import static util.MyLogger.log;
public class ProducerTask implements Runnable {
private BoundedQueue queue;
private String request;
public ProducerTask(BoundedQueue queue, String request) {
this.queue = queue;
this.request = request;
}
@Override
public void run() {
log("[생산 시도] " + request + " -> " + queue);
queue.put(request);
log("[생산 완료] " + request + " -> " + queue);
}
}- ProducerTask : 데이터를 생성하는 생성자 스레드가 실행하는 클래스, Runnable을 구현한다.
- 스레드를 실행하면 , queue.put(request)을 호출해서 전달된 데이터 (request)를 큐에 보관한다.
package thread.bounded;
import static util.MyLogger.log;
public class ConsumerTask implements Runnable {
private BoundedQueue queue;
public ConsumerTask(BoundedQueue queue) {
this.queue = queue;
}
@Override
public void run() {
log("[소비 시도] ? <- " + queue);
String data = queue.take();
log("[소비 완료] " + data + " <- " + queue);
}
}
- ConsumerTask: 데이터를 소비하는 소비자 스레드가 실행하는 클래스, Runnable을 구현한다.
- 스레드를 실행하면, queue.take()를 호출해서 큐의 데이터를 가져와서 소비한다.
package thread.bounded;
import java.util.ArrayList;
import java.util.List;
import static util.MyLogger.log;
import static util.ThreadUtils.sleep;
public class BoundedMain {
public static void main(String[] args) {
// 1. BoundedQueue 선택
BoundedQueue queue = new BoundedQueueV1(2);
//BoundedQueue queue = new BoundedQueueV2(2);
//BoundedQueue queue = new BoundedQueueV3(2);
//BoundedQueue queue = new BoundedQueueV4(2);
//BoundedQueue queue = new BoundedQueueV5(2);
//BoundedQueue queue = new BoundedQueueV6_1(2);
//BoundedQueue queue = new BoundedQueueV6_2(2);
//BoundedQueue queue = new BoundedQueueV6_3(2);
// BoundedQueue queue = new BoundedQueueV6_4(2);
// 2. 생산자, 소비자 실행 순서 선택, 반드시 하나만 선택!
// producerFirst(queue);
consumerFirst(queue);
// producerFirst(queue); // 생산자 먼저 실행
//consumerFirst(queue); // 소비자 먼저 실행
}
private static void producerFirst(BoundedQueue queue) {
log("== [생산자 먼저 실행] 시작, " + queue.getClass().getSimpleName() + " ==");
List<Thread> threads = new ArrayList<>();
startProducer(queue, threads);
printAllState(queue, threads);
startConsumer(queue, threads);
printAllState(queue, threads);
log("== [생산자 먼저 실행] 종료, " + queue.getClass().getSimpleName() + " ==");
}
private static void consumerFirst(BoundedQueue queue) {
log("== [소비자 먼저 실행] 시작, " + queue.getClass().getSimpleName() + " ==");
List<Thread> threads = new ArrayList<>();
startConsumer(queue, threads);
printAllState(queue, threads);
startProducer(queue, threads);
printAllState(queue, threads);
log("== [소비자 먼저 실행] 종료, " + queue.getClass().getSimpleName() + " ==");
}
private static void startProducer(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("생산자 시작");
for (int i = 1; i <= 3; i++) {
Thread producer = new Thread(new ProducerTask(queue, "data" + i), "producer" + i);
threads.add(producer);
producer.start();
sleep(100);
}
}
private static void startConsumer(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("소비자 시작");
for (int i = 1; i <= 3; i++) {
Thread consumer = new Thread(new ConsumerTask(queue), "consumer" + i);
threads.add(consumer);
consumer.start();
sleep(100);
}
}
private static void printAllState(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("현재 상태 출력, 큐 데이터: " + queue);
for (Thread thread : threads) {
log(thread.getName() + ": " + thread.getState());
}
}
}- 프로그램을 실행하는 코드이다.
- 여기서는 큐와 생산자 소비자의 실행 순서를 선택할 수 있어야 한다.
1. BoundedQueue 선택
BoundedQueue queue = new BoundedQueueV1(2);
BoundedQueue의
- 버퍼의 크기를 2를 사용한다. 데이터를 추가로 저장하려고 하면 문제가 발생할 수 있다.
- 버퍼의 크기는 2를 사용한다. 따라서 버퍼에는 데이터를 2개까지만 보관할 수 있다.
- 만약 생산자가 2개를 넘어서는 데이터를 추가로 저장하려고 하면 문제가 발행한다.
- 반대로 버퍼에 데이터가 없는데, 소비자가 데이터를 가져갈 때도 문제가 발생한다.
2. 생산자, 소비자 실행 순서 선택, 반드시 하나만 선택
producerFirst(queue); // 생산자 먼저 실행
//consumerFirst(queue); // 소비자 먼저 실행
이 두 코드 중에 하나만 선택해서 실행해야 한다. 그렇지 않으면, 예상치 못한 오류가 발생할 수 있다. 생산자가 먼저 실행되는 경우, 소비자가 먼저 실행되는 경우를 나누어서 다양한 예시를 보여주기 위해 이렇게 만들었다
producerFirst 코드 분석
private static void producerFirst(BoundedQueue queue) {
log("== [생산자 먼저 실행] 시작, " + queue.getClass().getSimpleName() + " ==");
List<Thread> threads = new ArrayList<>();
startProducer(queue, threads);
printAllState(queue, threads);
startConsumer(queue, threads);
printAllState(queue, threads);
log("== [생산자 먼저 실행] 종료, " + queue.getClass().getSimpleName() + " ==");
}
- threads : 스레드의 결과 상태를 한꺼번에 출력하기 위해 생성한 스레드를 보관해 줌
- startProducer : 생산자를 3개 만들어서 실행한다. 참고로 이해를 돕기 위해 0.1초의 간격으로 sleep을 주면서 순차적으로 실행한다. 이렇게 하면 producer1 -> producer2 -> producer3 순서로 실행되는 것을 확인할 수 있다.
- printAllState : 모든 스레드의 상태를 출력한다. 처음에는 producer 스레드들만 만들어졌으므로 해당 스레드들만 출력한다.
- startConsumer : 소비자 스레드를 3개 만들어서 실행한다. 참고로 이해를 돕기 위해 0.1초의 간격으로 sleep 을 주면서 순차적으로 실행한다. 이렇게 하면 consumer1 -> consumer2 -> consumer3 순서로 실행되는 것을 확인 할 수 있다.
- printAllState : 모든 스레드의 상태를 출력한다. 이때는 생산자 소비자 스레드 모두 출력한다.
여기서 핵심은 스레드를 0.1초 단위로 쉬면서 순서대로 실행한다는 점이다.
- 생산자 먼저인 producerFirst를 호출하면
- producer1 -> producer2 -> producer3 -> consumer1 -> consumer2 -> consumer3 순서로 실행된다.
- 소비자 먼저인 consumerFirst를 호출하면
- consumer1 -> consumer2 -> consumer3 -> producer1 -> producer2 -> producer3 순서로 실행된다.
참고로 여기서는 이해를 돕기 위해 이렇게 순서대로 실행했다. 실제로는 동시에 실행될 것이다.
생산자 먼저 실행
실행 순서를 분석하기 전에 우선 다음과 같이 생산자 먼저 실행해서 제대로 작동하는지 확인해 보자.
// 1. BoundedQueue 선택
BoundedQueue queue = new BoundedQueueV1(2);
// 2. 생산자, 소비자 실행 순서 선택, 반드시 하나만 선택!
producerFirst(queue);
// consumerFirst(queue);
실행 결과 - BoundedQueueV1, 생산자 먼저 실행

소비자 먼저 실행
이번에는 소비자를 먼저 실행해서 제대로 작동하는지 확인해 보자
// 1. BoundedQueue 선택
BoundedQueue queue = new BoundedQueueV1(2);
// 2. 생산자, 소비자 실행 순서 선택, 반드시 하나만 선택!
//producerFirst(queue);
consumerFirst(queue);
실행 결과 - BoundedQueueV1, 소비자 먼저 실행

생산자 소비자 문제 - 예제 1 분석 - 생산자 우선
그림을 통해 생산자 소비자 문제를 알아보자. 먼저 앞서 만든 예제 1의 실행 순서를 하나씩 분석해 보자.
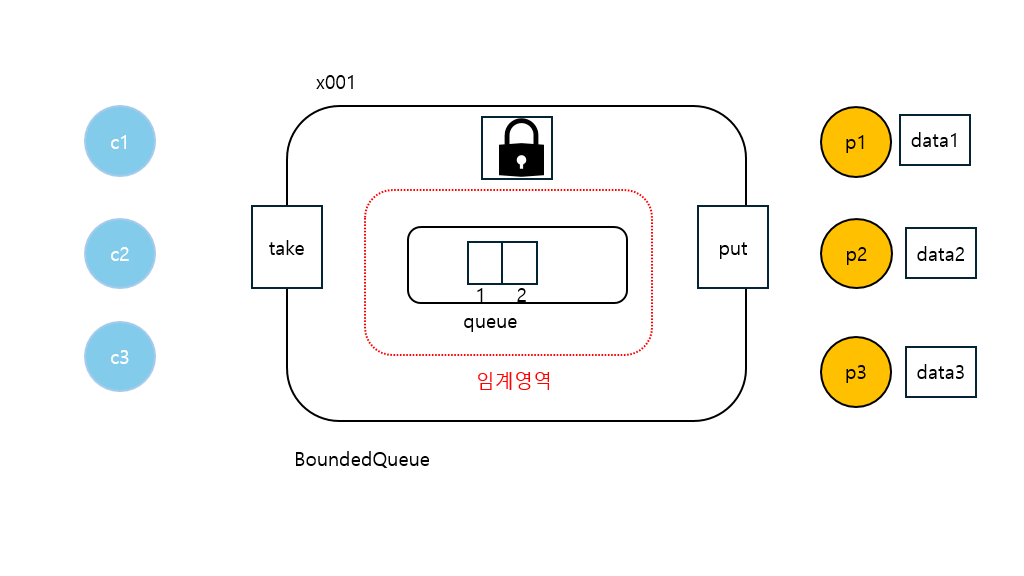
- p1 : producer1 생산자 스레드를 뜻한다.
- c1: consumer1 소비자 스레드를 뜻한다.
- 임계 영역은 synchronized를 적용한 영역을 뜻한다. 스레드가 이 영역에 들어가려면 모니터 락(lock) 이 필요하다.
- 설명을 단순화하기 위해
- BoundedQueueu의 버전 정보를 생략한다.
- 스레드가 처음부터 모두 생성되어 있는 것은 아니지만, 모두 그려두고 시작하겠다
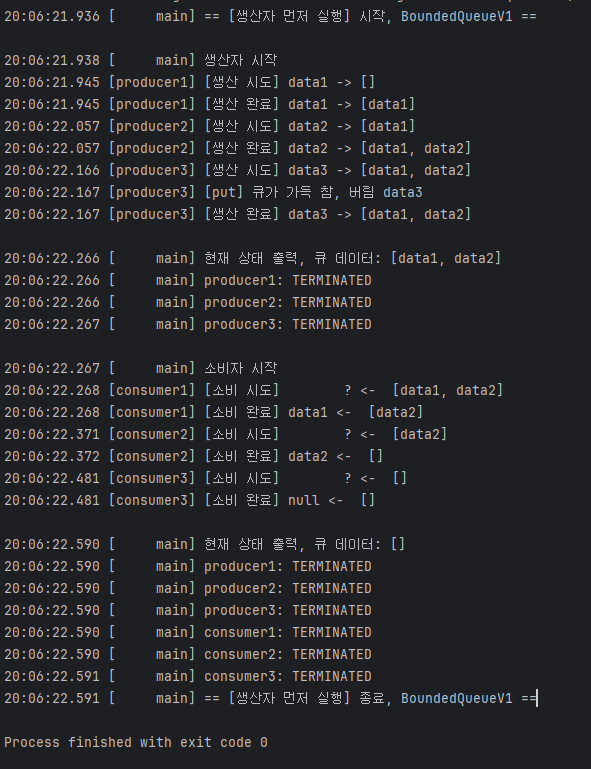
생산자 스레드 실행 시작
20:06:21.936 [ main] == [생산자 먼저 실행] 시작, BoundedQueueV1 ==
20:06:21.938 [ main] 생산자 시작
20:06:21.945 [producer1] [생산 시도] data1 -> []

20:06:21.945 [producer1] [생산 완료] data1 -> [data1]
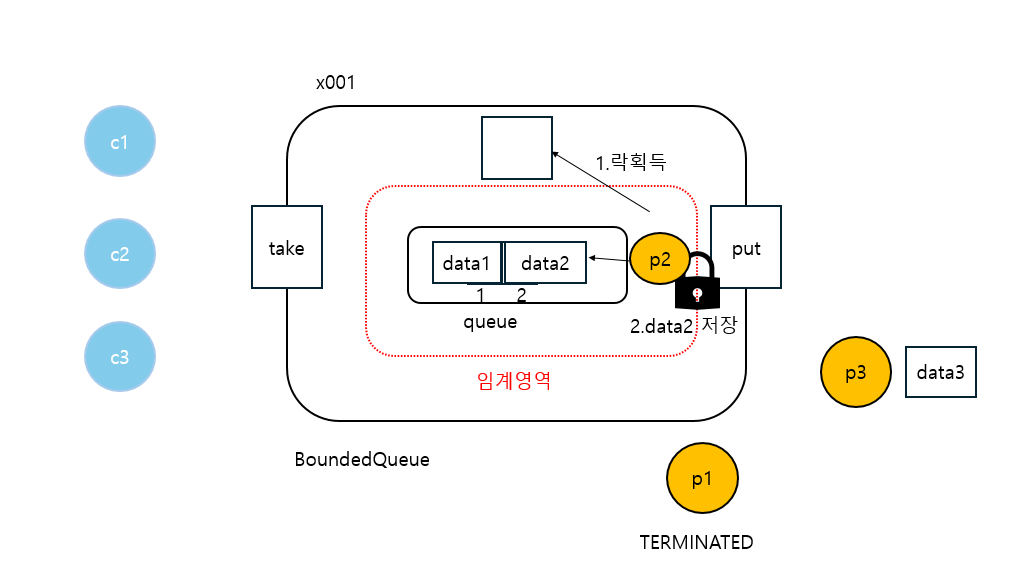
20:06:22.057 [producer2] [생산 시도] data2 -> [data1]
20:06:22.057 [producer2] [생산 완료] data2 -> [data1, data2]

20:06:22.166 [producer3] [생산 시도] data3 -> [data1, data2]
20:06:22.167 [producer3] [put] 큐가 가득 참, 버림 data3
p3는 data3을 큐에 저장하려고 시도한다.
하지만 큐가 가득 차 있기 때문에 더는 큐에 데이터를 추가할 수 없다. 따라서 put() 내부에서 data3은 버린다.
데이터를 버리지 않는 대안
data3을 버리지 않은 대안은, 큐에 빈 공간이 생길 때까지 p3 스레드가 기다리는 것이다. 언젠가는 소비자 스레드가 실행되어서 큐의 데이터를 가져갈 것이고, 큐에 빈 공간이 생기게 된다. 이때 큐의 데이터를 보관하는 것이다.
그럼 어떻게 기다릴 수 있을까?
단순하게 생각하면 생산자 스레드가 반복문을 사용해서 큐에 빈 공간이 생기는지 주기적으로 체크한 다음에, 만약 빈 공간이 없다면 sleep()을 짧게 사용해서 잠시 대기하고, 깨어난 다음에 다시 반복문에서 큐의 빈 공간을 체크하는 식으로 구현하면 될 것 같다.
이후에 BoundedQueueV2에서 이 방식으로 개선해 보자
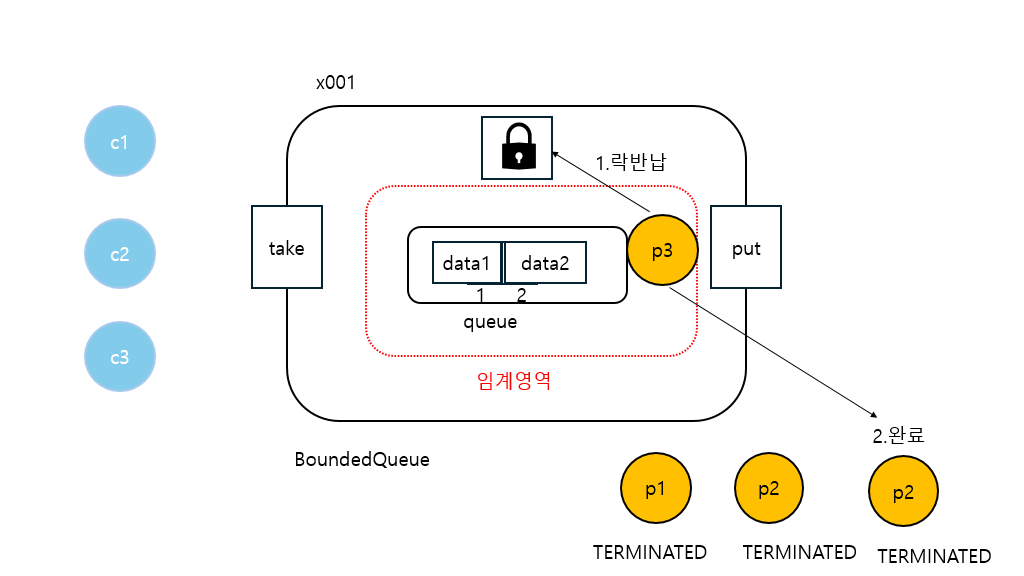
20:06:22.167 [producer3] [생산 완료] data3 -> [data1, data2]

20:06:22.266 [ main] 현재 상태 출력, 큐 데이터: [data1, data2]
20:06:22.266 [ main] producer1: TERMINATED
20:06:22.266 [ main] producer2: TERMINATED
20:06:22.267 [ main] producer3: TERMINATED

20:06:22.267 [ main] 소비자 시작
20:06:22.268 [consumer1] [소비 시도] ? <- [data1, data2]
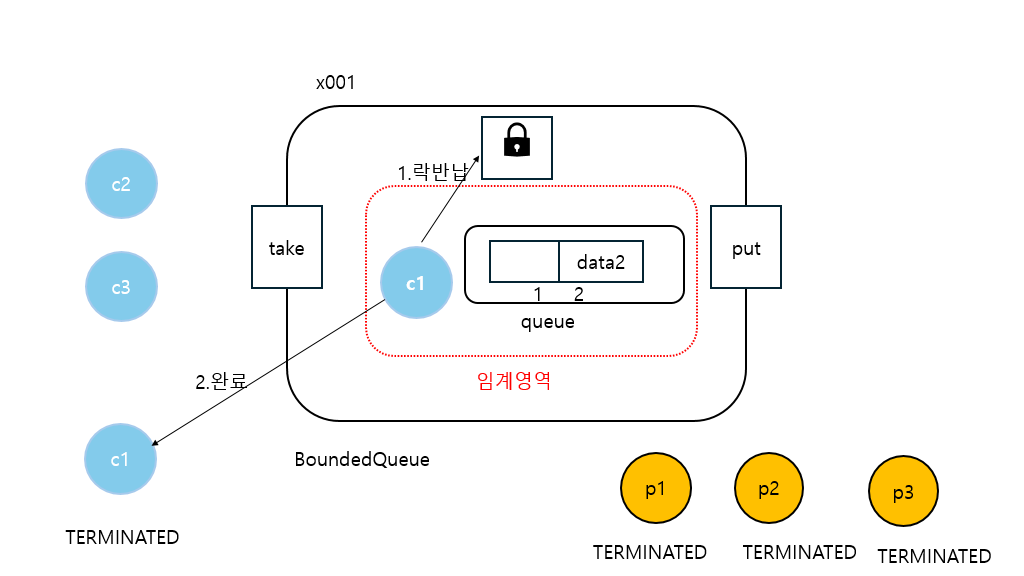
20:06:22.268 [consumer1] [소비 완료] data1 <- [data2]

20:06:22.371 [consumer2] [소비 시도] ? <- [data2]
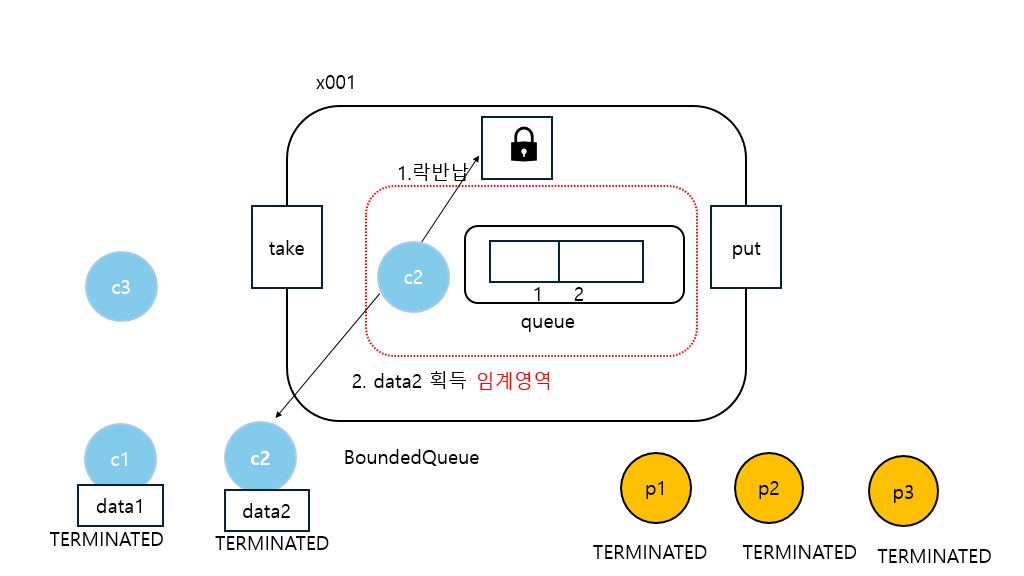
20:06:22.372 [consumer2] [소비 완료] data2 <- []
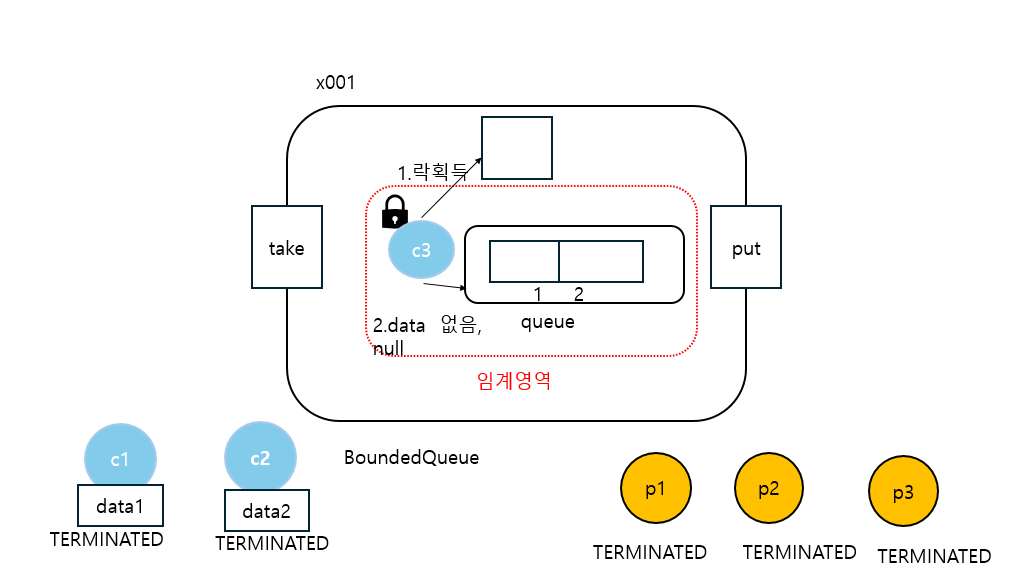
20:06:22.481 [consumer3] [소비 시도] ? <- []
c3는 큐에서 데이터를 획득하려고 한다. 하지만 큐에 데이터가 없기 때문에 데이터를 획득할 수 없다. 따라서 대신에 null을 반환한다.
큐에 데이터가 없다면 기다리 자소비자 입장에서 큐에 데이터가 없다면 기다리는 것도 대안이다. null을 받지 않은 대안은, 큐에 데이터가 추가될 때까지 c3 스레드가 기다리는 것이다. 언젠가는 생산자 스레드가 실행되어서 큐에 데이터를 추가할 것이다. 물론 생산자 스레드가 걔속해서 데이터를 생산한다는 가정이 필요하다.
그럼 어떻게 기다릴 수 있을까? 단순하게 생각하면 소비자 스레드가 반복문을 사용해서 큐에 데이터가 있는지 주기적으로 체크한 다음에, 만약 데이터가 없다면 sleep()을 짧게 사용해서 대기하고 , 깨어난 다음에 다시 반복문에서 큐에 데이터가 있는지 체크하는 식으로 구현하면 될 것이다.
BoundedQueueV2 ` 에서 이 방식으로 개선해 보자
생각해 보면 큐에 데이터가 없는 상황은 앞서 큐의 데이터가 가득 찬 상황과 비슷하다. 한정된 버퍼(Bounded buffer) 문제는 이렇듯 버퍼에 데이터가 가득 찬 상황에 데이터를 생산해서 추가할 때도 문제가 발생하고, 큐에 데이터가 없는데 데이터를 소비할 때도 문제가 발생한다.

20:06:22.481 [consumer3] [소비 완료] null <- []

20:06:22.590 [ main] 현재 상태 출력, 큐 데이터: []
20:06:22.590 [ main] producer1: TERMINATED
20:06:22.590 [ main] producer2: TERMINATED
20:06:22.590 [ main] producer3: TERMINATED
20:06:22.590 [ main] consumer1: TERMINATED
20:06:22.590 [ main] consumer2: TERMINATED
20:06:22.591 [ main] consumer3: TERMINATED
20:06:22.591 [ main] == [생산자 먼저 실행] 종료, BoundedQueueV1 ==
결좌적으로 버퍼가 가득 차서 p3가 생산한 data3 은 버려졌다. 그리고 c3 가 데이터를 조회하는 시점에 버퍼는 비어있어서 데이터를 받지 못하고 null 값을 받았다. 스레드가 대기하며 기다릴 수 있다면 p3가 생산한 data3을 c3 가 받을 수도 있었을 것이다.
생산자 소비자 문제 - 예제 1 분석 - 소비자 우선
BoundedQueueV1 - 소비자 먼저 실행 분석
이번에는 반대로 소비자를 먼저 실행하고 그 결과를 분석해 보자
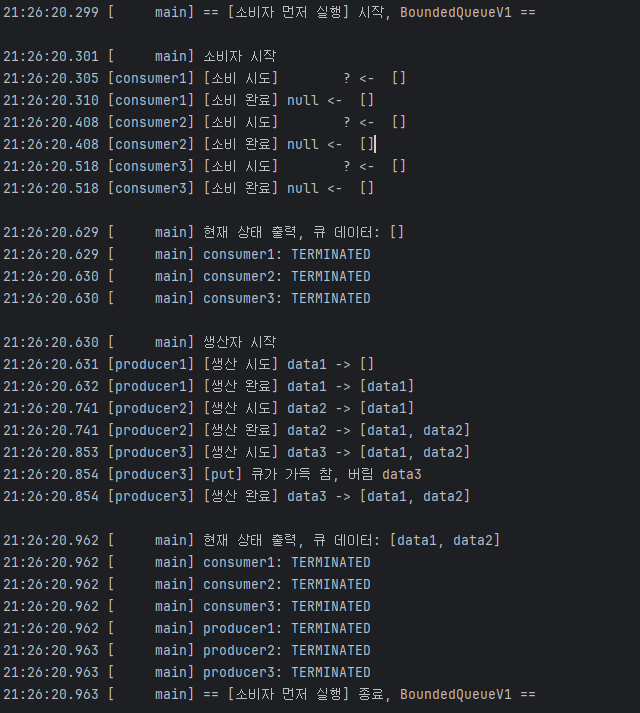
실행 전
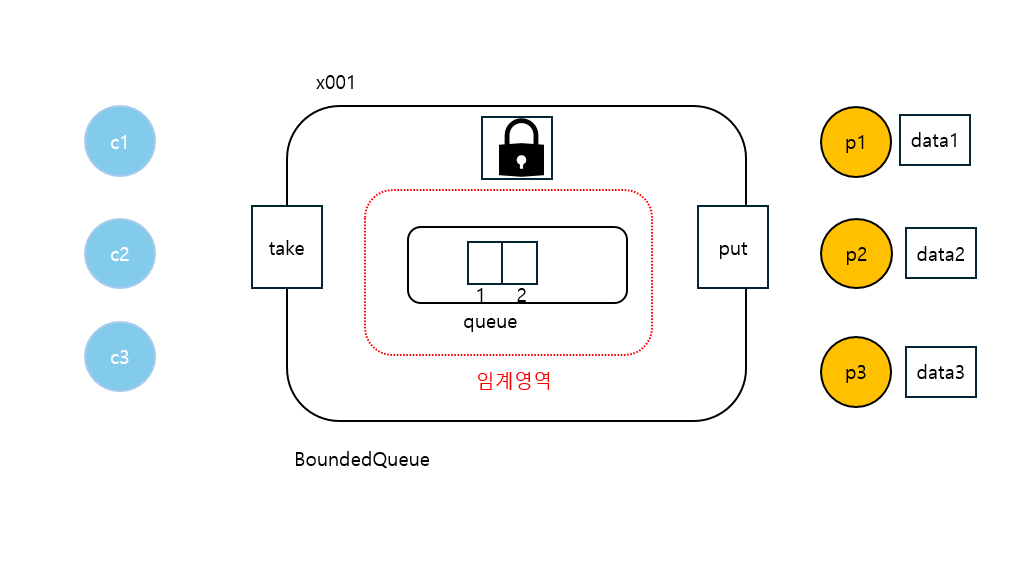
소비자 스레드 실행 시작

21:26:20.299 [ main] == [소비자 먼저 실행] 시작, BoundedQueueV1 ==
21:26:20.301 [ main] 소비자 시작
21:26:20.305 [consumer1] [소비 시도] ? <- []
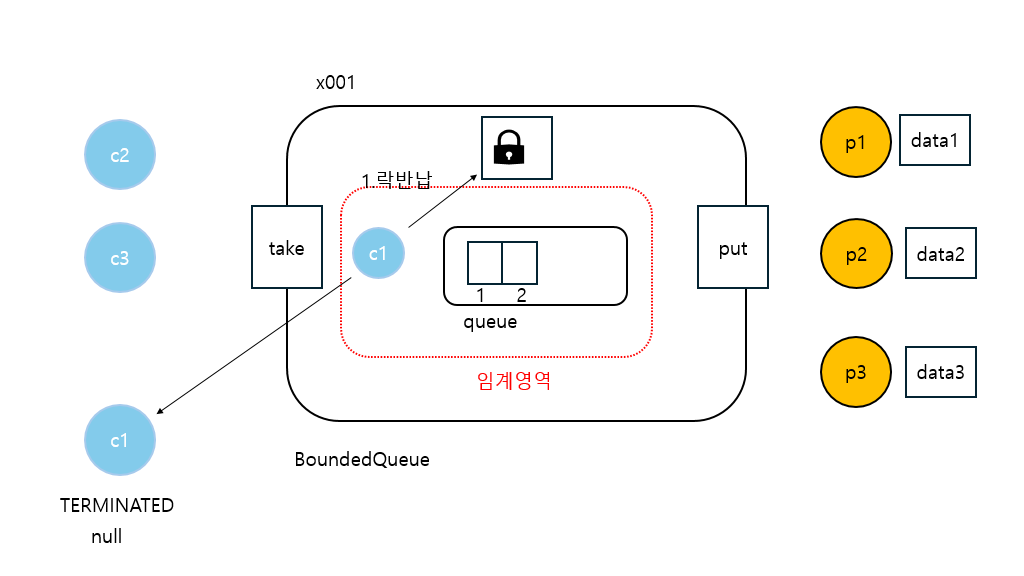
21:26:20.310 [consumer1] [소비 완료] null <- []
소비자 스레드 실행 완료

21:26:20.408 [consumer2] [소비 시도] ? <- []
21:26:20.408 [consumer2] [소비 완료] null <- []
21:26:20.518 [consumer3] [소비 시도] ? <- []
21:26:20.518 [consumer3] [소비 완료] null <- []
21:26:20.629 [ main] 현재 상태 출력, 큐 데이터: []
21:26:20.629 [ main] consumer1: TERMINATED
21:26:20.630 [ main] consumer2: TERMINATED
21:26:20.630 [ main] consumer3: TERMINATED
큐에 데이터가 없으므로 null을 반환한다. 결과적으로 c1, c2, c3 모두 데이터를 받지 못하고 종료된다.
언젠가 생산자가 데이터를 넣어준다고 가정해 보면 c1, c2, c3 스레드는 큐에 데이터가 추가될 때까지 기다리는 것도 방법이다. (이 부분은 뒤에서 구현한다.)
생산자 스레드 실행 시작
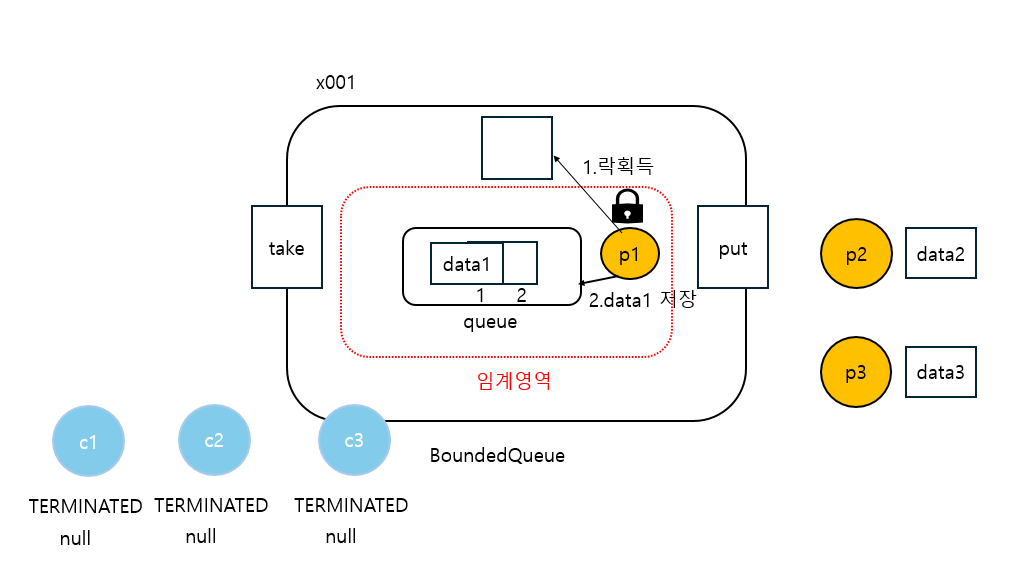
21:26:20.630 [ main] 생산자 시작
21:26:20.631 [producer1] [생산 시도] data1 -> []

21:26:20.632 [producer1] [생산 완료] data1 -> [data1]
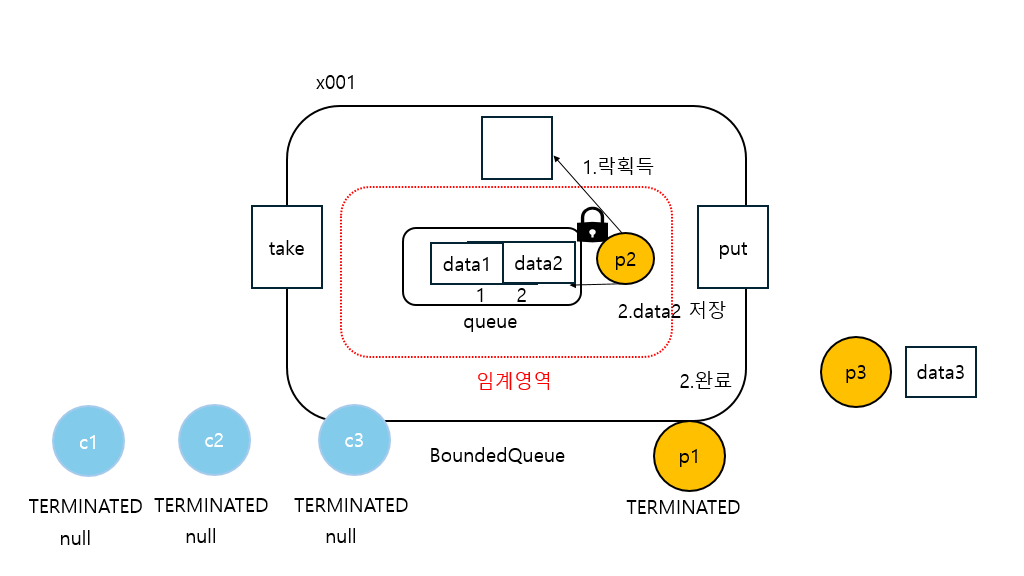
21:26:20.741 [producer2] [생산 시도] data2 -> [data1]
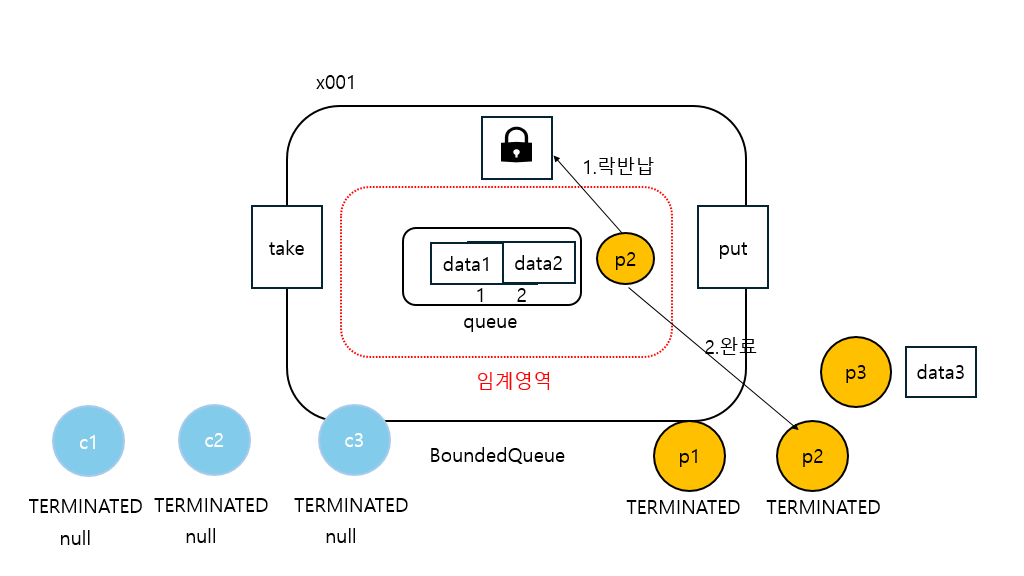
21:26:20.741 [producer2] [생산 완료] data2 -> [data1, data2]
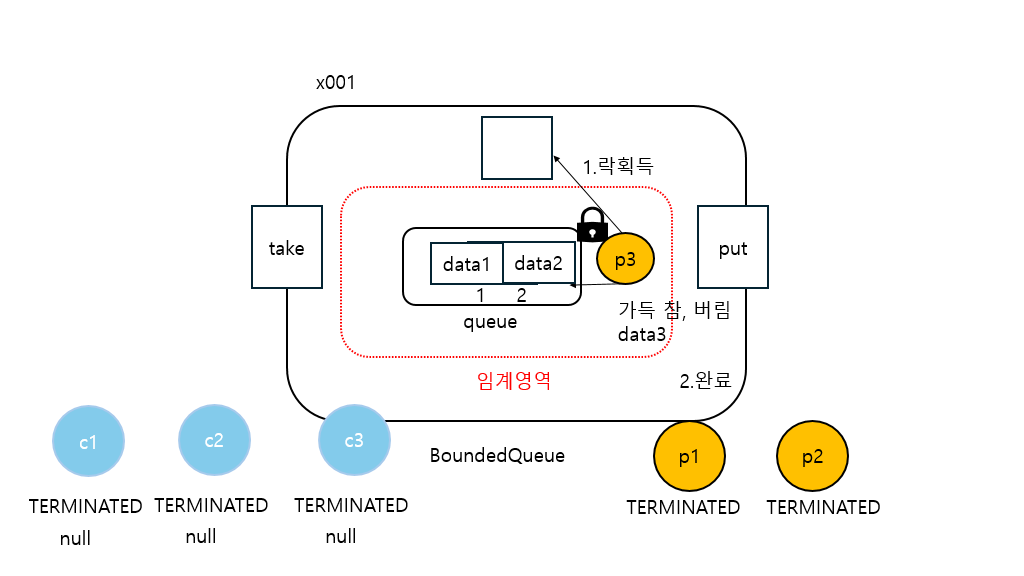
21:26:20.853 [producer3] [생산 시도] data3 -> [data1, data2]
21:26:20.854 [producer3] [put] 큐가 가득 참, 버림 data3

21:26:20.854 [producer3] [생산 완료] data3 -> [data1, data2]

21:26:20.962 [ main] 현재 상태 출력, 큐 데이터: [data1, data2]
21:26:20.962 [ main] consumer1: TERMINATED
21:26:20.962 [ main] consumer2: TERMINATED
21:26:20.962 [ main] consumer3: TERMINATED
21:26:20.962 [ main] producer1: TERMINATED
21:26:20.963 [ main] producer2: TERMINATED
21:26:20.963 [ main] producer3: TERMINATED
21:26:20.963 [ main] == [소비자 먼저 실행] 종료, BoundedQueueV1 ==
문제점
생산자 스레드 먼저 실행의 경우 p3 가 보관하는 data3은 버려지고, c3는 데이터를 받지 못한다. (null을 받는다.)
소비자 스레드 먼저 실행의 경우 c1, c2, c3 은 데이터를 받지 못한다. (null 을 받는다.) 그리고 p3가 보관하는 data3 은 버려진다.
예제는 단순하게 설명하기 위해 생산자 스레드 3개, 소비자 스레드 3개를 한 번만 실행했지만, 실제로 이런 생산자 소비자 구조는 보통 계속해서 실행된다. 레스토랑에 손님은 계속 찾아오고, 음료 공장은 계속해서 음료를 만들어 낸다.
쇼핑몰이라면 고객은 계속해서 주문은 한다.
버퍼가 가득 찬 경우 : 생산자 입장에서 버퍼에 여유가 생길 때까지 조금만 기다리며 되는데, 기다리지 못하고, 데이터를 버리는 것은 아쉽다.
버퍼가 빈 경우 : 소비자 입장에서 버퍼에 데이터가 채워질 때까지 조금만 기다리면 되는데, 기다리지 못하고 null 데이터를 얻는 것은 아쉽다.
문제의 해결 방안은 단순한다. 앞서 설명한 것처럼 스레드가 기다리면 되는 것이다. 그럼 기다리도록 구현해 보자.
참고자료 : 김영한의 실전 자바 고급 1편
'JAVA' 카테고리의 다른 글
| Java에서의 지연 초기화,지연 평가 Optional 활용: orElse vs orElseGet (0) | 2025.01.06 |
|---|---|
| 고급 동기화 - concurrent.Lock (1) | 2025.01.05 |
| 메모리 가시성 (0) | 2024.12.29 |
| 익명 클래스 (0) | 2024.12.24 |
| 중첩 클래스, 내부 클래스 2 (1) | 2024.12.24 |